Dan Rosenbaum

I am a Senior Lecturer (Assistant Professor) in the Department of Computer Science at the University of Haifa, working on machine learning, computer vision and AI for science.
Before joining the University of Haifa I was a research scientist at DeepMind (2016-2021). I completed my PhD at the Hebrew University of Jerusalem in 2016, advised by Yair Weiss, studying generative models for low-level vision problems. [thesis]
I am interested in computational models of perception, 3D scene understanding, simulation-based inference and machine learning for scientific discovery. I focus on generative approaches that model perception as a probabilistic inverse problem.
- learning models of 3D scenes that can be used for probabilistic inference.
- learning continuous and discrete representations of continuous signals.
- amortizing simulation-based inference.
- scientific discovery using flexible probabilistic modeling of the data acquisition process.
I co-organised a workshop at NeurIPS 2019 titled “Perception as Generative Reasoning: Structure, Causality, Probability”.
See the website for all papers, invited talks and videos.
Research
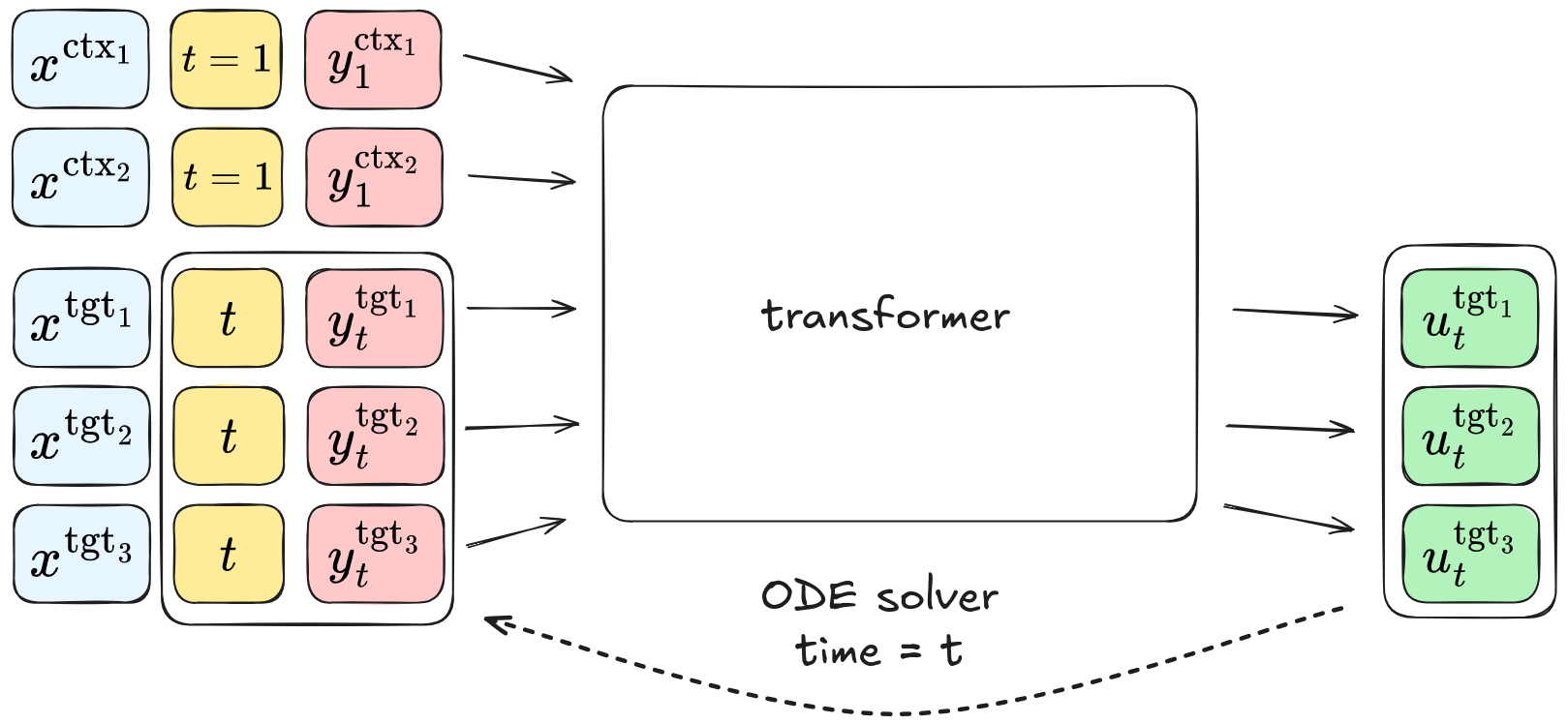 Flow Matching Neural Processes - In this work OpenReview (NeurIPS 2025) we introduce a Neural Process (NP) model based on Flow Matching. The model is simple to implement, trains efficiently and allows parallel generation of target points with amortizing conditoining on context points.
This approach achieves state-of-the-art performance on benchmarks ranging from 1D functions to real-world weather data (ERA5).
Flow Matching Neural Processes - In this work OpenReview (NeurIPS 2025) we introduce a Neural Process (NP) model based on Flow Matching. The model is simple to implement, trains efficiently and allows parallel generation of target points with amortizing conditoining on context points.
This approach achieves state-of-the-art performance on benchmarks ranging from 1D functions to real-world weather data (ERA5).
 Underwater perception - In collaboration with the School of Marine Sciences, I have worked on several projects on underwater perception problems. In SeaThru-Nerf (CVPR 2023) we model underwater 3D scenes by adapting NeRF to scattering media rendering;
in Osmosis (ECCV 2024) we tackle underwater image restoration using posterior sampling with an RGBD diffusion prior;
and in Looking into the water (NeurIPS 2025) we fix water refraction using a physics-informed neural field approach.
Underwater perception - In collaboration with the School of Marine Sciences, I have worked on several projects on underwater perception problems. In SeaThru-Nerf (CVPR 2023) we model underwater 3D scenes by adapting NeRF to scattering media rendering;
in Osmosis (ECCV 2024) we tackle underwater image restoration using posterior sampling with an RGBD diffusion prior;
and in Looking into the water (NeurIPS 2025) we fix water refraction using a physics-informed neural field approach.
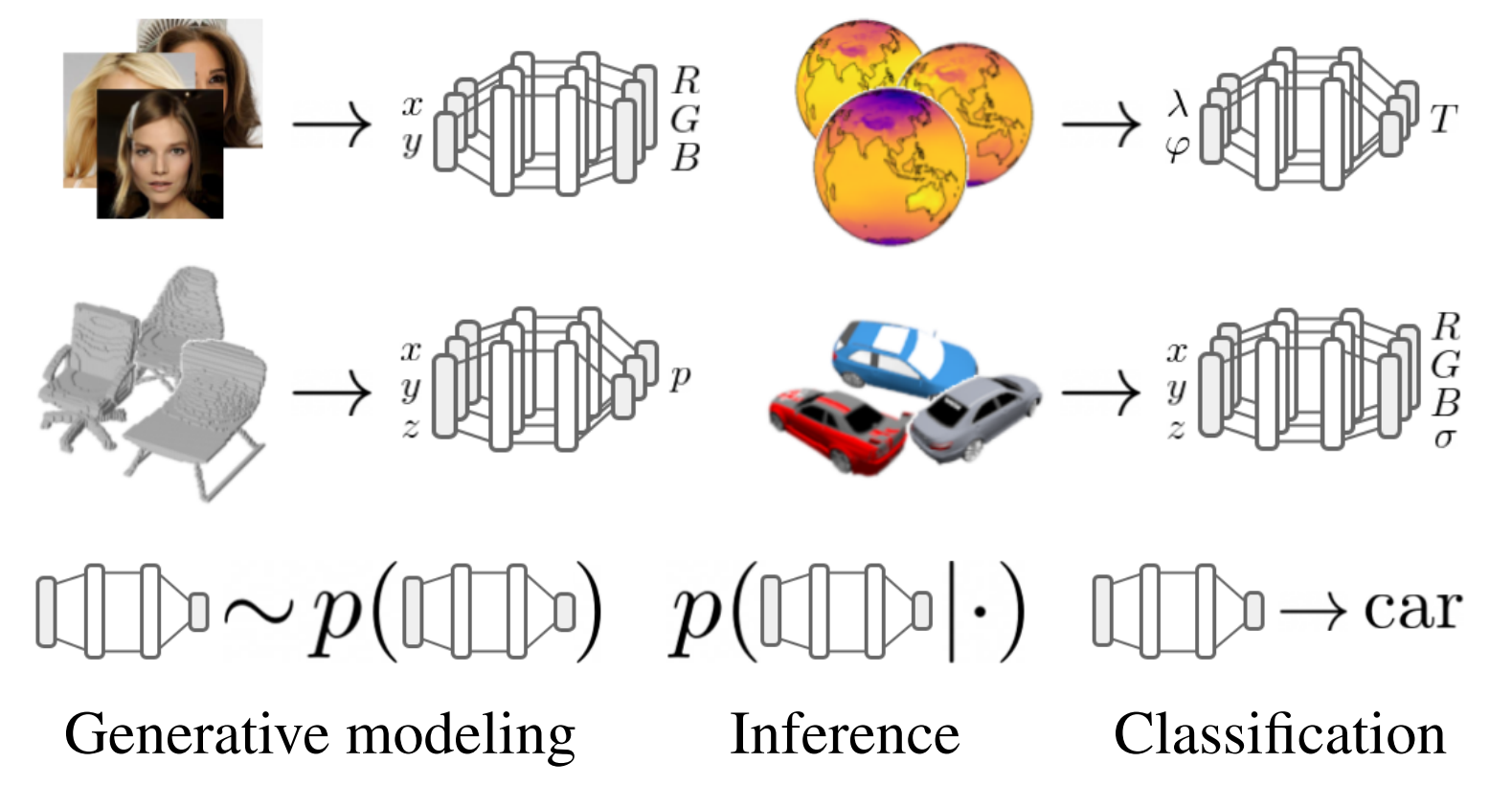 Functa: data as neural fields - In these two papers, arXiv (ICML 2022) and arXiv (ICLR Neural Fields workshop 2023), we explore the representation of data points such as images, manyfolds, 3D shapes and scense using neural fields (aka implicit neural representations). Many standard data representations are a discretization of an underlying continuous signal, and can be more efficiently modeled as functions. We develop a method to map samples of datasets to a functional represention, and demonstrate the benefits of training generative models or classifiers on this representation.
Functa: data as neural fields - In these two papers, arXiv (ICML 2022) and arXiv (ICLR Neural Fields workshop 2023), we explore the representation of data points such as images, manyfolds, 3D shapes and scense using neural fields (aka implicit neural representations). Many standard data representations are a discretization of an underlying continuous signal, and can be more efficiently modeled as functions. We develop a method to map samples of datasets to a functional represention, and demonstrate the benefits of training generative models or classifiers on this representation.
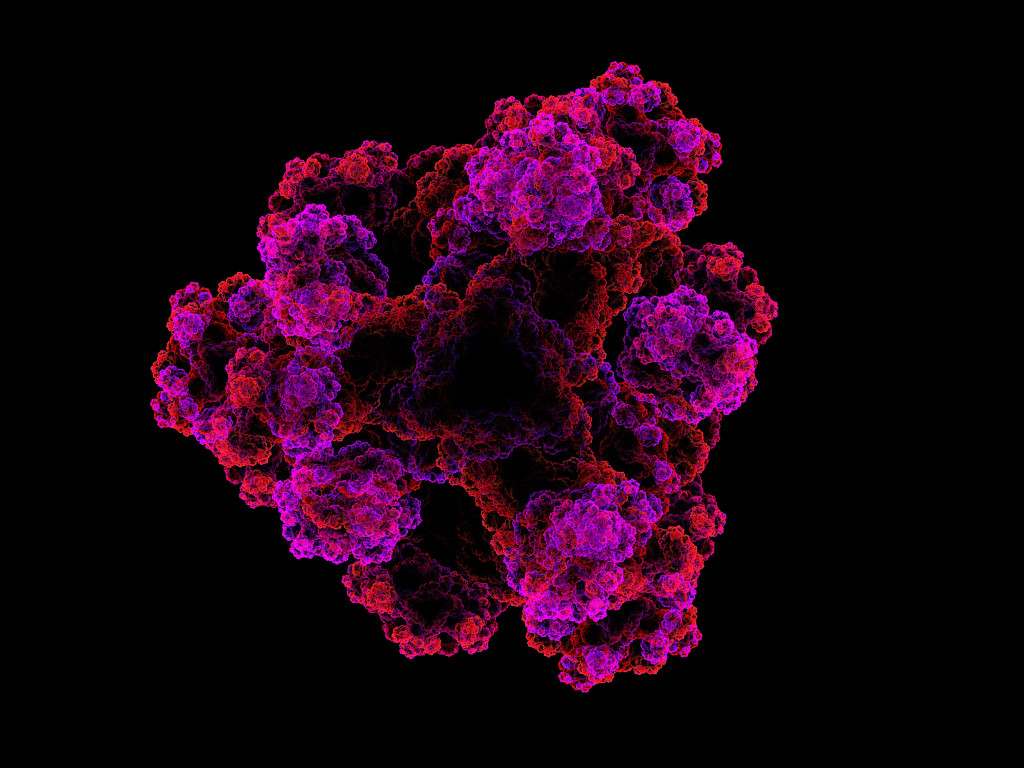 Dynamic Protein Structure - Understanding the 3D structure of proteins is a fundamental problem in biology, with the potential of unlocking a better understanding of the various functions of proteins in biological mechanisms, and accelerating drug discovery. I am studying models of protein structure that explicitly reason in 3D space, predicting structure using probabilistic inference methods.
In this work arXiv (NeurIPS Structured Biology workshop 2021) we propose an inverse graphics approach based on VAEs to model the distribution of protein 3D structure in atom space, using cryo-EM image data.
Dynamic Protein Structure - Understanding the 3D structure of proteins is a fundamental problem in biology, with the potential of unlocking a better understanding of the various functions of proteins in biological mechanisms, and accelerating drug discovery. I am studying models of protein structure that explicitly reason in 3D space, predicting structure using probabilistic inference methods.
In this work arXiv (NeurIPS Structured Biology workshop 2021) we propose an inverse graphics approach based on VAEs to model the distribution of protein 3D structure in atom space, using cryo-EM image data.
 3D scene understanding with Generative Query Network (GQN) - In this paper (Science) we show how implicit scene understanding can emerge from training a model to predict novel views of random 3D scenes (video). In a follow-up paper arXiv (NeurIPS Bayesian ML workshop 2018) we extend the model to use attention over image patches, improving its capacity to model rich environments like Minecaft. We study the camera pose estimation problem comparing an inference method with a generative model to a direct discriminative approach (video, datasets).
3D scene understanding with Generative Query Network (GQN) - In this paper (Science) we show how implicit scene understanding can emerge from training a model to predict novel views of random 3D scenes (video). In a follow-up paper arXiv (NeurIPS Bayesian ML workshop 2018) we extend the model to use attention over image patches, improving its capacity to model rich environments like Minecaft. We study the camera pose estimation problem comparing an inference method with a generative model to a direct discriminative approach (video, datasets).
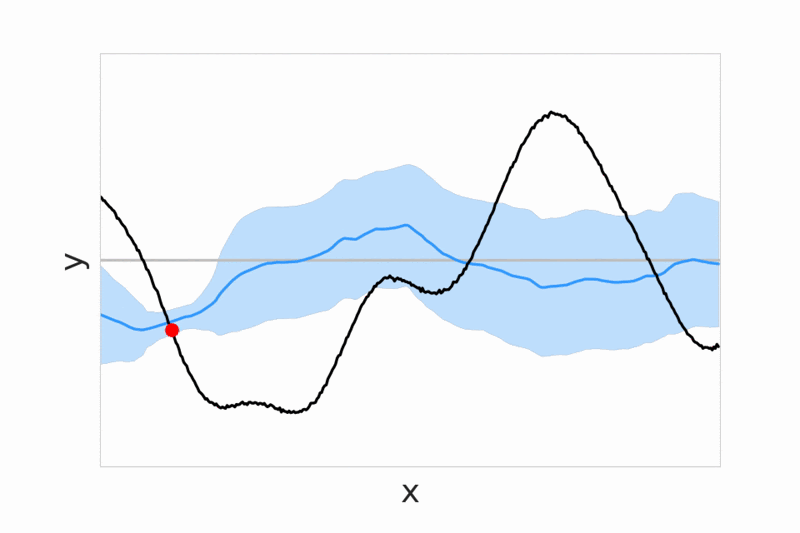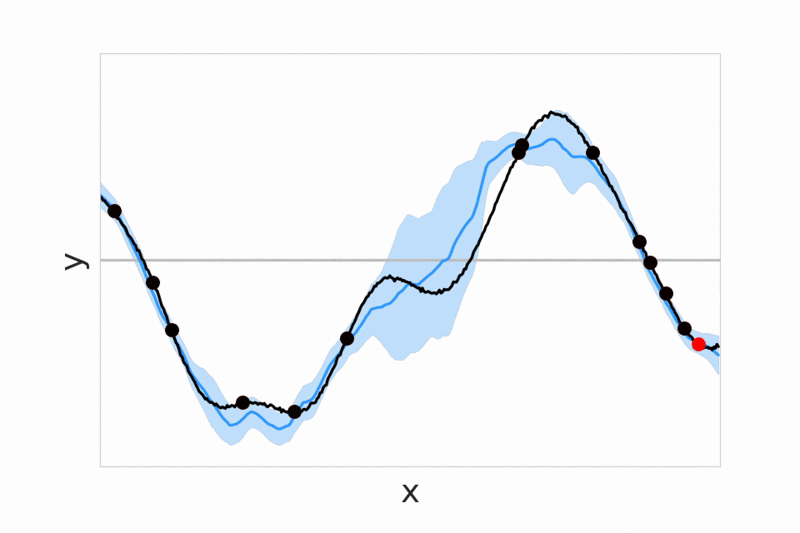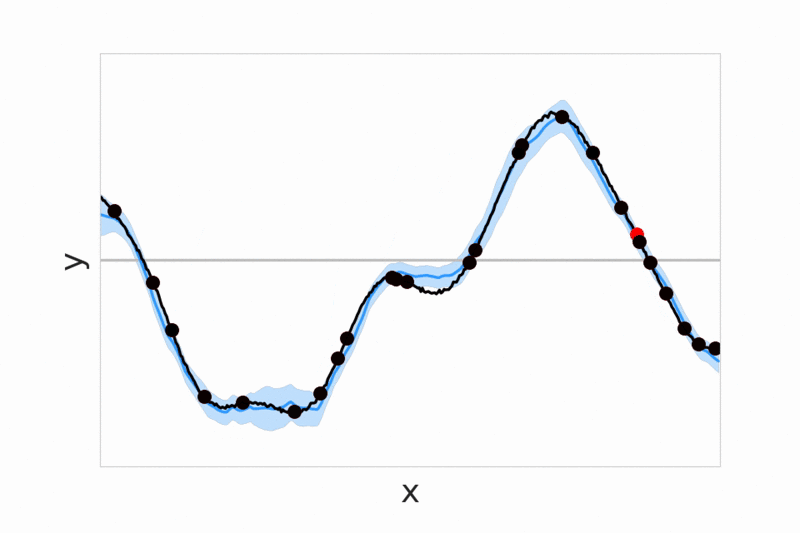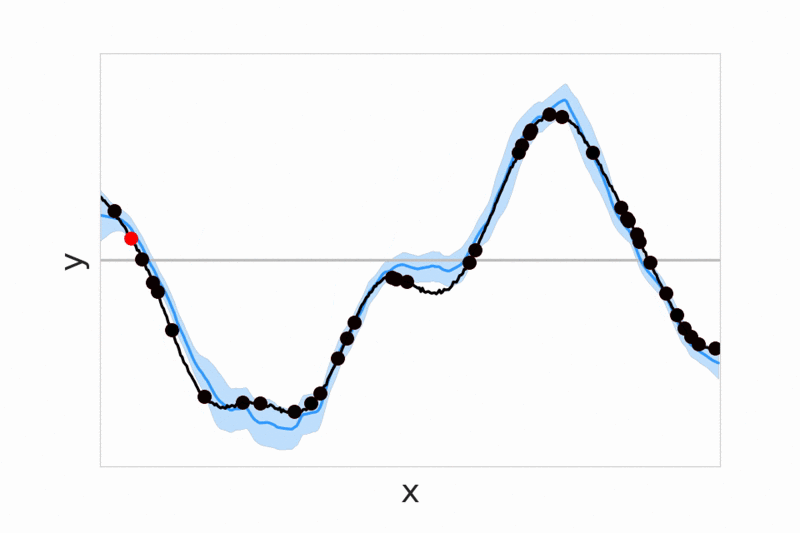 Neural processes - We introduce conditional neural processes arXiv (ICML 2018) and neural processes arXiv (ICML Bayesian ML workshop), that are trained to predict values of functions given a context of observed function evaluations. These models provide a general framework for dealing with uncertainty, demonstrating fast adaptivity, and allowing a smooth transition between a prior model that is not conditioned on any data, and flexible posterior models which can be conditioned on more and more data. In follow-up work we extend the model with an attention mechanism over context points (arXiv) and study different training objectives (pdf).
Neural processes - We introduce conditional neural processes arXiv (ICML 2018) and neural processes arXiv (ICML Bayesian ML workshop), that are trained to predict values of functions given a context of observed function evaluations. These models provide a general framework for dealing with uncertainty, demonstrating fast adaptivity, and allowing a smooth transition between a prior model that is not conditioned on any data, and flexible posterior models which can be conditioned on more and more data. In follow-up work we extend the model with an attention mechanism over context points (arXiv) and study different training objectives (pdf).
Contact
 danro@cs.haifa.ac.il
danro@cs.haifa.ac.il